
Understanding K-Nearest Neighbours (KNN): A Practical Approach to Predictive Intelligence
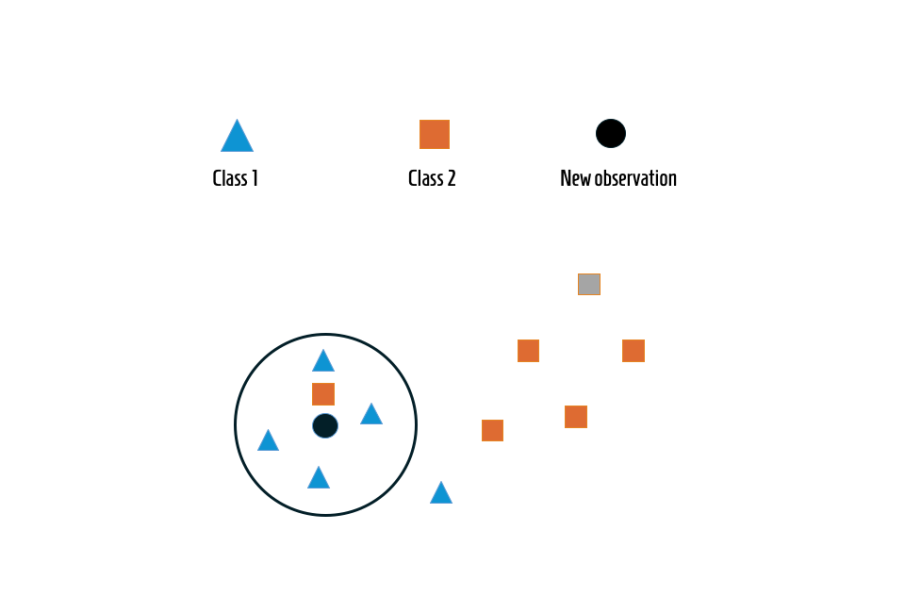
In the realm of Artificial Intelligence (AI), some algorithms are like elegant minimalists—simple in form yet powerful in function. The K-Nearest Neighbours (KNN) algorithm is one such example. It doesn’t rely on heavy computations or complex model training; instead, it learns by observation, much like how humans identify patterns through experience. KNN reminds us that even in a world dominated by deep learning and massive neural networks, simplicity still holds immense power.
Learning by Example: The Essence of KNN
Imagine walking into a new city and trying to find a good restaurant. You might ask locals where they usually dine. If most of them point to a specific spot, you’ll likely trust their recommendation. That’s precisely how KNN works—it makes predictions by comparing an unknown data point to its nearest neighbours.
Instead of memorising complex mathematical relationships, KNN classifies or predicts outcomes based on proximity—meaning it looks at the closest data points and lets them “vote” on the decision. This lazy learning approach, where computation happens only when needed, makes KNN both intuitive and highly interpretable.
Professionals exploring structured learning through an AI course in Chennai often start with KNN because it introduces fundamental ideas like distance metrics, data normalisation, and decision boundaries—concepts that form the foundation of more advanced algorithms later in their journey.
The Art of Measuring Similarity
KNN’s magic lies in measuring similarity. The closer the neighbours, the greater their influence on the prediction. Distance metrics such as Euclidean, Manhattan, or Minkowski define how “closeness” is determined.
Choosing the right distance measure is like selecting the right lens for a camera—it affects what you see. For image recognition, Euclidean distance often works well, while for text classification or recommendation systems, cosine similarity might provide better accuracy.
But precision depends on more than just distance. Data scaling plays a crucial role, too. Without normalising features, one large numerical value (like income) could overshadow smaller ones (like age), skewing the results.
KNN teaches an important lesson about fairness: every feature, no matter how small, deserves to have its voice heard—a concept that resonates deeply in ethical AI development.
Choosing the Right ‘K’: The Balancing Act
At the heart of KNN lies a deceptively simple question: how many neighbours should we consider? This parameter, K, determines how sensitive the model is to noise and variation.
- A small K (say 1 or 3) makes the model highly sensitive, possibly overfitting to outliers.
- A large K smooths out the decision boundary but risks oversimplifying the data.
Finding the right K is an art of balance—too much rigidity can make the model narrow-minded, while too much leniency can make it indecisive.
Tuning K often involves cross-validation and iterative experimentation, reinforcing the principle that even simple algorithms demand thoughtful calibration.
Strengths and Limitations in the Real World
KNN shines in scenarios where interpretability and quick implementation are key. It’s ideal for recommendation engines, pattern recognition, and even fraud detection—domains where context matters as much as computation.
However, its biggest strength—simplicity—can also be a weakness. KNN’s reliance on all available data means that as datasets grow, the algorithm becomes slower and more memory-intensive.
To overcome this, professionals often employ optimisations like KD-trees or Ball Trees to speed up nearest-neighbour searches. These techniques reduce computational load without compromising accuracy, demonstrating how modern engineering enhances even the most classical algorithms.
Many learners pursuing an AI course in Chennai experiment with such optimisations to appreciate how theory translates into practical efficiency. They learn not only to build models but also to scale them gracefully for real-world applications.
KNN in Context: Learning Through Proximity
In a broader sense, KNN reflects how humans learn—not through abstraction but through comparison. When we make choices, we often look to our “neighbours”—similar experiences, past data, or peer behaviours.
KNN captures that essence of relational learning. It reminds data scientists that intelligence doesn’t always mean memorising rules; sometimes, it means observing relationships and acting based on collective wisdom.
Conclusion
K-Nearest Neighbours may be one of the oldest algorithms in the AI toolkit, but its relevance endures because it embodies the spirit of simplicity and adaptability. It’s the quiet observer that waits until the right question is asked, then answers based on what it knows from its neighbours.
For professionals entering the field of artificial intelligence, mastering intuitive algorithms is essential for developing both technical skills and conceptual understanding. Enrolling in a program provides not only the theoretical foundation needed to comprehend K-Nearest Neighbours (KNN) but also practical experience in applying it effectively—bridging the gap between data and intelligent decision-making.
In the evolving landscape of AI, KNN stands as a timeless reminder: sometimes, the smartest solutions are also the simplest.










